Code
%load_ext autoreload
%autoreload 2
from IPython.display import Image, display%load_ext autoreload
%autoreload 2
from IPython.display import Image, displayPlease see the guide on interactive results review for a general review of how to download and review results. Here we use the same approach without any of the explanatory text to retrieve model results to generate plots for model selection and evaluation.
In this notebook we illustrate how to download and review results using unrealistic downsampled data. Therefore, this notebook should not be taken to represent the results of applying the model to real data.
from pyrovelocity.io.cluster import get_remote_task_results
# execution_id = "pyrovelocity-py311-defaul-fe20d09-dev-pzh-17b5092261c84e8695a" # downsampled
execution_id = (
"pyrovelocity-595-gsmc-feaa936-dev-vf0-264734a284ac493fa39" # complete
)
(
model1_postprocessing_inputs,
model1_postprocessing_outputs,
) = get_remote_task_results(
execution_id=execution_id,
task_id="f26c1pjy-0-dn1-0-dn3",
)
(
model2_postprocessing_inputs,
model2_postprocessing_outputs,
) = get_remote_task_results(
execution_id=execution_id,
task_id="f26c1pjy-0-dn1-0-dn7",
)└── postprocess_configuration: number_posterior_samples: 30.0 preprocess_data_args: adata: data/external/pancreas.h5ad cell_state: clusters count_threshold: 0.0 data_processed_path: data/processed data_set_name: pancreas default_velocity_mode: dynamical min_shared_counts: 30.0 n_neighbors: 30.0 n_obs_subset: 300.0 n_pcs: 30.0 n_top_genes: 2000.0 n_vars_subset: 200.0 overwrite: false process_cytotrace: true use_obs_subset: false use_vars_subset: false vector_field_basis: umap training_outputs: data_model: pancreas_model1 data_model_path: models/pancreas_model1 loss_plot_path: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/sw/flfip54y/072cd31b52f928ca1277d2da8a7a7f05/ELBO.png metrics_path: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/sw/flfip54y/0030a6c56ba3fdadf4b0af178038523d/metrics.json model_path: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/sw/flfip54y/896904dca80ab80eb8962871325c24e3 posterior_samples_path: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/sw/flfip54y/88a07607d3e59f3112f976c785c79b98/posterior_samples.pkl.zst run_info_path: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/sw/flfip54y/68e1a9eb3ee47ce007f6804567f9fefd/run_info.json trained_data_path: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/sw/flfip54y/8cd0d1d241a5c2096da3cbd125bcb59b/trained.h5ad
└── o0: postprocessed_data: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/t6/fetgomfi/3e4844e172c3c1a373e564a991bf210b/postprocessed.h5ad pyrovelocity_data: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/t6/fetgomfi/e9bad79fc3eb1b970fdf0d2e6d834e35/pyrovelocity.pkl.zst
└── postprocess_configuration: number_posterior_samples: 30.0 preprocess_data_args: adata: data/external/pancreas.h5ad cell_state: clusters count_threshold: 0.0 data_processed_path: data/processed data_set_name: pancreas default_velocity_mode: dynamical min_shared_counts: 30.0 n_neighbors: 30.0 n_obs_subset: 300.0 n_pcs: 30.0 n_top_genes: 2000.0 n_vars_subset: 200.0 overwrite: false process_cytotrace: true use_obs_subset: false use_vars_subset: false vector_field_basis: umap training_outputs: data_model: pancreas_model2 data_model_path: models/pancreas_model2 loss_plot_path: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/9r/fbucfxyy/8403bb004c57db42195b02e367ef5081/ELBO.png metrics_path: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/9r/fbucfxyy/786b484cab5fa8eb2a831c18decdfa11/metrics.json model_path: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/9r/fbucfxyy/22eb165bc78f4af578bd1037ca46e19e posterior_samples_path: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/9r/fbucfxyy/af9e7531bca61530162936bbd447d6f8/posterior_samples.pkl.zst run_info_path: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/9r/fbucfxyy/1f70c93816ec8626553a8b59d05128a9/run_info.json trained_data_path: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/9r/fbucfxyy/359b307225eb1e95335c948ad66dbc61/trained.h5ad
└── o0: postprocessed_data: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/wp/fkav4jki/66f2a973f4955d74a02d42770444344d/postprocessed.h5ad pyrovelocity_data: path: gs://pyro-284215-flyte-user-pyrovelocity-dev/data/wp/fkav4jki/9969d8f03e8614681fad4096d955f64d/pyrovelocity.pkl.zst
from pyrovelocity.io.gcs import download_blob_from_uri
model1_pyrovelocity_data = download_blob_from_uri(
blob_uri=model1_postprocessing_outputs.o0.pyrovelocity_data.path,
download_filename_prefix=f"{model1_postprocessing_inputs.training_outputs.data_model}",
)
model1_postprocessed_data = download_blob_from_uri(
blob_uri=model1_postprocessing_outputs.o0.postprocessed_data.path,
download_filename_prefix=f"{model1_postprocessing_inputs.training_outputs.data_model}",
)
model2_pyrovelocity_data = download_blob_from_uri(
blob_uri=model2_postprocessing_outputs.o0.pyrovelocity_data.path,
download_filename_prefix=f"{model2_postprocessing_inputs.training_outputs.data_model}",
)
model2_postprocessed_data = download_blob_from_uri(
blob_uri=model2_postprocessing_outputs.o0.postprocessed_data.path,
download_filename_prefix=f"{model2_postprocessing_inputs.training_outputs.data_model}",
)[19:33:10] INFO pyrovelocity.io.gcs File pancreas_model1_pyrovelocity.pkl.zst already exists. The hash of the requested file has not been checked. Delete and re-run to download again.
[19:33:11] INFO pyrovelocity.io.gcs File pancreas_model1_postprocessed.h5ad already exists. The hash of the requested file has not been checked. Delete and re-run to download again.
INFO pyrovelocity.io.gcs File pancreas_model2_pyrovelocity.pkl.zst already exists. The hash of the requested file has not been checked. Delete and re-run to download again.
[19:33:12] INFO pyrovelocity.io.gcs File pancreas_model2_postprocessed.h5ad already exists. The hash of the requested file has not been checked. Delete and re-run to download again.
import scanpy as sc
from pyrovelocity.utils import print_anndata
adata = sc.read(model1_postprocessed_data)
print_anndata(adata)INFO pyrovelocity.utils AnnData object with n_obs × n_vars = 3696 × 2000 obs: clusters_coarse, clusters, S_score, G2M_score, u_lib_size_raw, s_lib_size_raw, gcs, cytotrace, counts, initial_size_unspliced, initial_size_spliced, initial_size, n_counts, leiden, velocity_self_transition, root_cells, end_points, velocity_pseudotime, latent_time, u_lib_size, s_lib_size, u_lib_size_mean, s_lib_size_mean, u_lib_size_scale, s_lib_size_scale, ind_x, cell_time, 1-Cytotrace, velocity_pyro_self_transition, var: highly_variable_genes, cytotrace, cytotrace_corrs, gene_count_corr, means, dispersions, dispersions_norm, highly_variable, fit_r2, fit_alpha, fit_beta, fit_gamma, fit_t_, fit_scaling, fit_std_u, fit_std_s, fit_likelihood, fit_u0, fit_s0, fit_pval_steady, fit_steady_u, fit_steady_s, fit_variance, fit_alignment_scaling, velocity_genes, uns: _scvi_manager_uuid, _scvi_uuid, clusters_coarse_colors, clusters_colors, day_colors, leiden, log1p, neighbors, pca, recover_dynamics, velocity_graph, velocity_graph_neg, velocity_params, velocity_pyro_graph, velocity_pyro_graph_neg, velocity_pyro_params, obsm: X_pca, X_umap, velocity_pyro_pca, velocity_pyro_umap, velocity_umap, varm: PCs, loss, layers: Ms, Mu, fit_t, fit_tau, fit_tau_, raw_spliced, raw_unspliced, spliced, spliced_pyro, unspliced, velocity, velocity_pyro, velocity_u, obsp: connectivities, distances,
from pyrovelocity.utils import pretty_print_dict
from pyrovelocity.io import CompressedPickle
posterior_samples = CompressedPickle.load(model1_pyrovelocity_data)
pretty_print_dict(posterior_samples)[19:33:13] INFO pyrovelocity.utils alpha: (30, 1, 2000) gamma: (30, 1, 2000) beta: (30, 1, 2000) t0: (30, 1, 2000) u_scale: (30, 1, 2000) dt_switching: (30, 1, 2000) u_inf: (30, 1, 2000) s_inf: (30, 1, 2000) switching: (30, 1, 2000) cell_time: (30, 3696, 1) u_read_depth: (30, 3696, 1) s_read_depth: (30, 3696, 1) cell_gene_state: (30, 3696, 2000) gene_ranking: mean_mae time_correlation mean_mae_rank time_correlation_rank \ genes Pdia6 -0.720178 0.999334 77.0 1.0 Calr -0.657205 0.999204 58.0 2.0 Sec61g -0.936153 0.997772 178.0 3.0 Rpn2 -0.873851 0.988811 140.0 5.0 Dlk1 -0.923083 0.987080 163.0 6.0 ... ... ... ... ... Mt1 -0.708479 -0.896828 72.0 250.0 Clu -0.665874 -0.902599 61.0 228.0 Lurap1l -0.868574 -0.906450 138.0 217.0 Csrp1 -1.043720 -0.908675 252.0 206.0 H19 -0.720566 -0.912351 78.0 189.0 rank_product selected genes genes Pdia6 77.0 1 Calr 116.0 1 Sec61g 534.0 1 Rpn2 700.0 1 Dlk1 978.0 0 ... ... ... Mt1 18000.0 0 Clu 13908.0 0 Lurap1l 29946.0 0 Csrp1 51912.0 0 H19 14742.0 0 [300 rows x 6 columns] original_spaces_embeds_magnitude: (30, 3696) genes: ['Pdia6', 'Calr', 'Sec61g', 'Rpn2'] vector_field_posterior_samples: (30, 3696, 2) vector_field_posterior_mean: (3696, 2) fdri: (3696,) embeds_magnitude: (30, 3696) embeds_angle: (30, 3696) ut_mean: (3696, 2000) st_mean: (3696, 2000) pca_vector_field_posterior_samples: (30, 3696, 50) pca_embeds_angle: (30, 3696) pca_fdri: (3696,)
We decompose the correlation of each gene’s expression level with the cell time estimates into eight equally-spaced bins and select the top 3% of genes with respect to the mean absolute error between the predictive sample mean and the observed expression level.
from pyrovelocity.analysis.analyze import top_mae_genes
volcano_data = posterior_samples["gene_ranking"]
number_of_marker_genes = min(
max(int(len(volcano_data) * 0.1), 4), 6, len(volcano_data)
)
putative_marker_genes = top_mae_genes(
volcano_data,
mae_top_percentile=3,
min_genes_per_bin=3,
)INFO pyrovelocity.analysis.analyze Selected 26 genes based on top 3% MAE from 8 time correlation bins, with a minimum of 3 genes per bin, sorted by time correlation: ['Ctrb1', 'Malat1', 'H3f3b', 'Actb', 'Actg1', 'Hspa8', 'Cdk4', 'Ins2', 'Krt8', 'Arl6ip1', 'Myl12b', 'Ranbp1', 'Gapdh', 'Mif', 'Pebp1', 'Myl12a', 'Krt18', 'Mgst1', 'Cdkn1c', 'Tpm1', 'Tead2', 'Acot1', 'Vim', 'Spp1', 'Sparc', 'Clu']
We generate several summary plots below for two distinct model classes in order to support comparative model evaluation, which is among few options for selecting effective models that are not designed to be microscopically valid.
Here we plot the gene selection statistics highlighting genes of interest based upon them.
from pyrovelocity.plots import plot_gene_ranking
vector_field_basis = (
model1_postprocessing_inputs.preprocess_data_args.vector_field_basis
)
cell_state = model1_postprocessing_inputs.preprocess_data_args.cell_state
plot_gene_ranking(
posterior_samples=[posterior_samples],
adata=[adata],
selected_genes=putative_marker_genes,
time_correlation_with="st",
show_marginal_histograms=True,
save_volcano_plot=True,
volcano_plot_path="model1_volcano_plot.pdf",
)display(Image(filename=f"model1_volcano_plot.pdf.png"))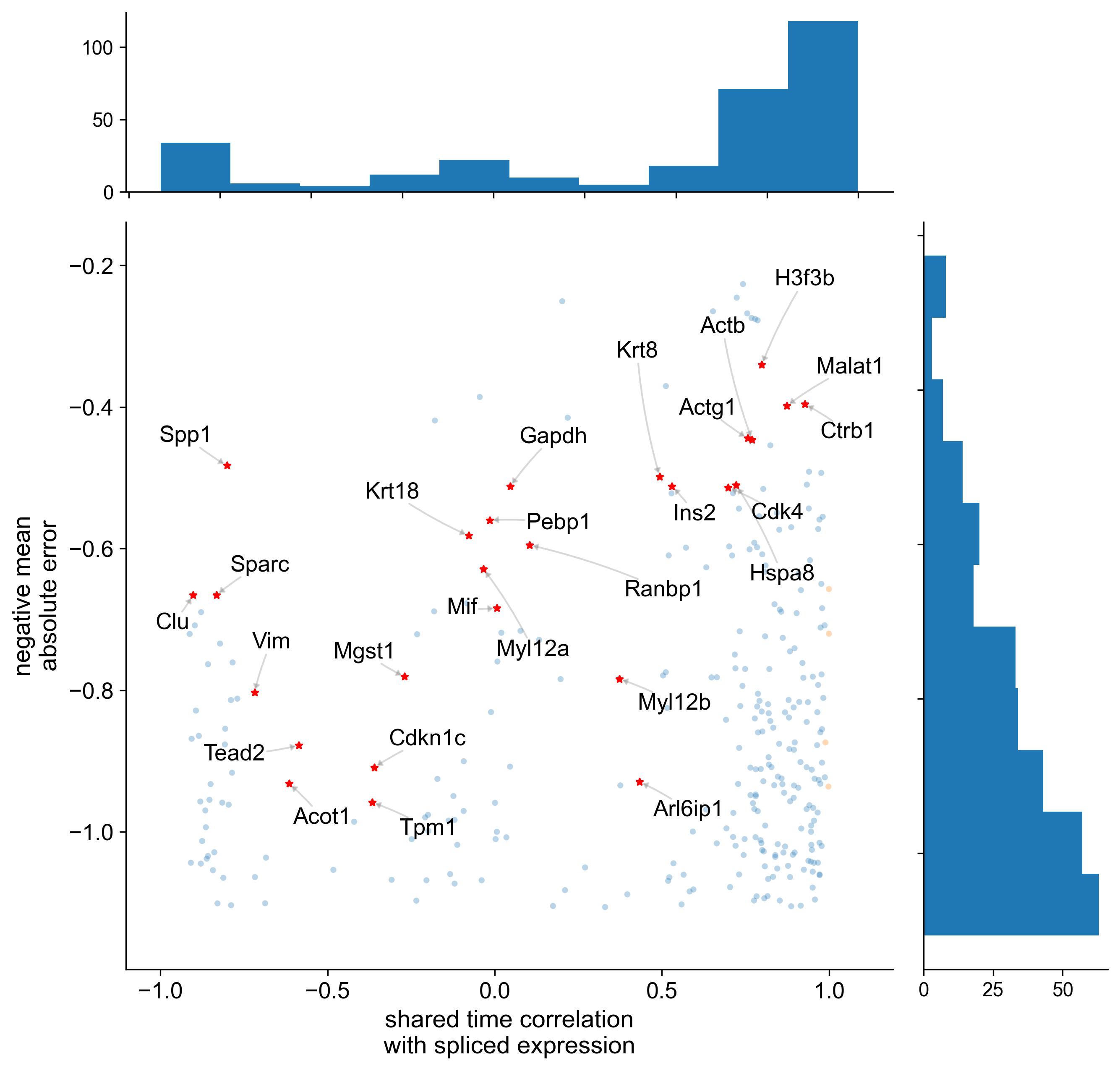
We can attempt to attribute the statistics to underlying features plotting phase portraits, predictive expression, and log-transformed expression of the proposed marker genes
from pyrovelocity.plots import rainbowplot
rainbowplot(
volcano_data=volcano_data,
adata=adata,
posterior_samples=posterior_samples,
genes=putative_marker_genes,
data=["st", "ut"],
basis=vector_field_basis,
cell_state=cell_state,
save_plot=True,
rainbow_plot_path="model1_rainbow_plot.pdf",
)display(Image(filename=f"model1_rainbow_plot.pdf.png"))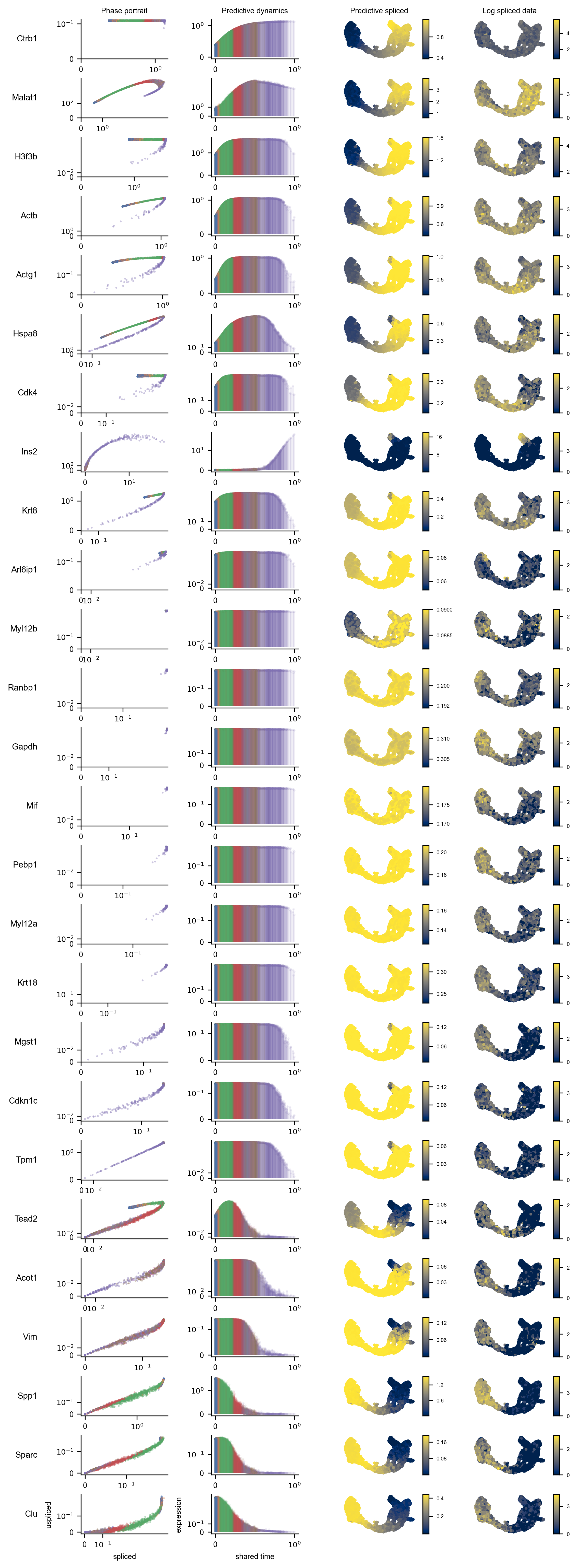
It is somewhat difficult to compare the parameter posteriors on a common scale but we plot their posterior distributions below.
from pyrovelocity.plots import plot_parameter_posterior_distributions
posterior_samples.pop("t0", None)
plot_parameter_posterior_distributions(
posterior_samples=posterior_samples,
adata=adata,
geneset=putative_marker_genes,
parameter_uncertainty_plot="model1_parameter_uncertainty_plot.pdf",
)display(Image(filename=f"model1_parameter_uncertainty_plot.pdf.png"))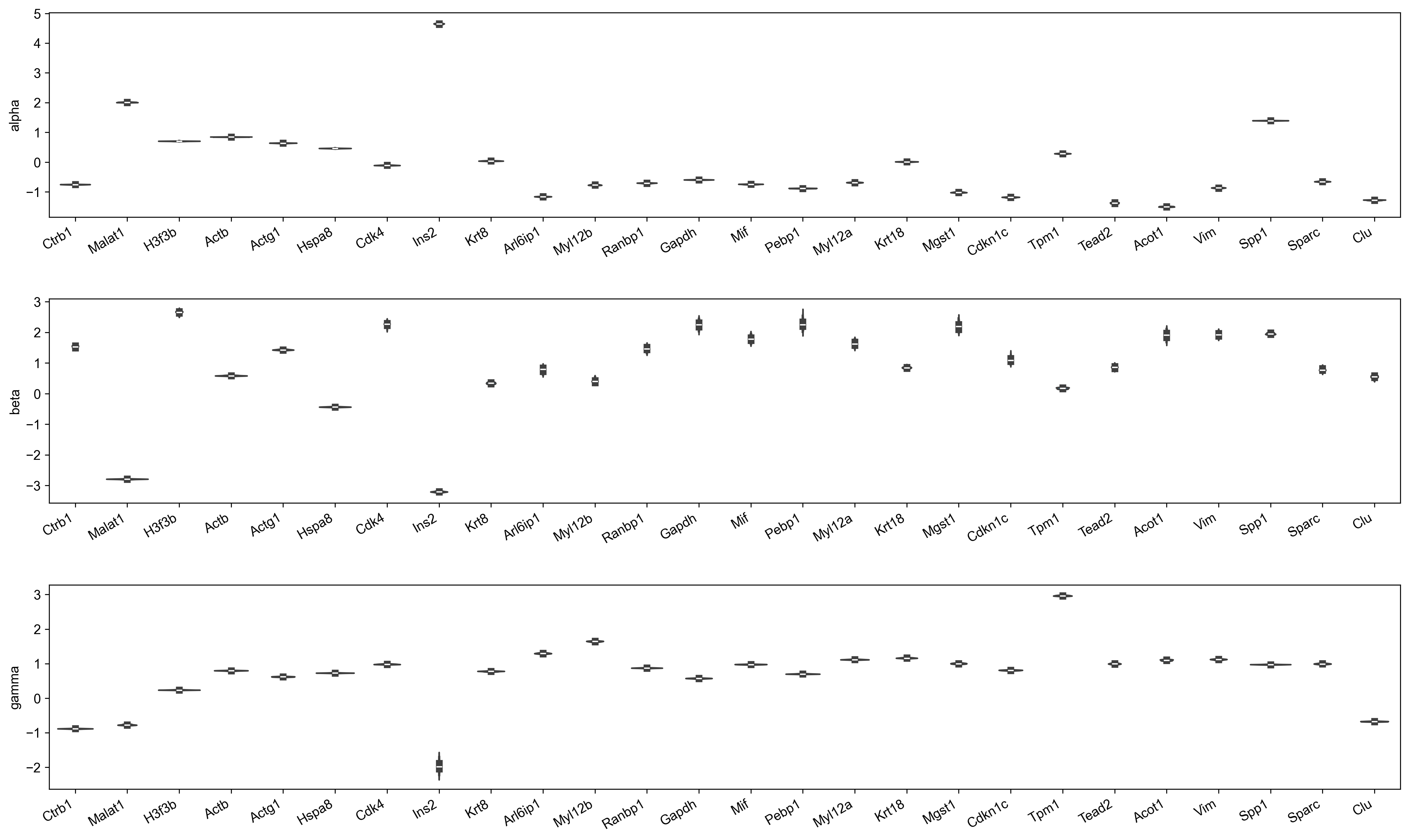
We provide a comparable analysis for the second model below.
import scanpy as sc
from pyrovelocity.utils import print_anndata
adata = sc.read(model2_postprocessed_data)
print_anndata(adata)[19:34:30] INFO pyrovelocity.utils AnnData object with n_obs × n_vars = 3696 × 2000 obs: clusters_coarse, clusters, S_score, G2M_score, u_lib_size_raw, s_lib_size_raw, gcs, cytotrace, counts, initial_size_unspliced, initial_size_spliced, initial_size, n_counts, leiden, velocity_self_transition, root_cells, end_points, velocity_pseudotime, latent_time, u_lib_size, s_lib_size, u_lib_size_mean, s_lib_size_mean, u_lib_size_scale, s_lib_size_scale, ind_x, cell_time, 1-Cytotrace, velocity_pyro_self_transition, var: highly_variable_genes, cytotrace, cytotrace_corrs, gene_count_corr, means, dispersions, dispersions_norm, highly_variable, fit_r2, fit_alpha, fit_beta, fit_gamma, fit_t_, fit_scaling, fit_std_u, fit_std_s, fit_likelihood, fit_u0, fit_s0, fit_pval_steady, fit_steady_u, fit_steady_s, fit_variance, fit_alignment_scaling, velocity_genes, uns: _scvi_manager_uuid, _scvi_uuid, clusters_coarse_colors, clusters_colors, day_colors, leiden, log1p, neighbors, pca, recover_dynamics, velocity_graph, velocity_graph_neg, velocity_params, velocity_pyro_graph, velocity_pyro_graph_neg, velocity_pyro_params, obsm: X_pca, X_umap, velocity_pyro_pca, velocity_pyro_umap, velocity_umap, varm: PCs, loss, layers: Ms, Mu, fit_t, fit_tau, fit_tau_, raw_spliced, raw_unspliced, spliced, spliced_pyro, unspliced, velocity, velocity_pyro, velocity_u, obsp: connectivities, distances,
from pyrovelocity.utils import pretty_print_dict
from pyrovelocity.io import CompressedPickle
posterior_samples = CompressedPickle.load(model2_pyrovelocity_data)
pretty_print_dict(posterior_samples)[19:34:32] INFO pyrovelocity.utils alpha: (30, 1, 2000) gamma: (30, 1, 2000) beta: (30, 1, 2000) u_offset: (30, 1, 2000) s_offset: (30, 1, 2000) t0: (30, 1, 2000) u_scale: (30, 1, 2000) dt_switching: (30, 1, 2000) u_inf: (30, 1, 2000) s_inf: (30, 1, 2000) switching: (30, 1, 2000) cell_time: (30, 3696, 1) u_read_depth: (30, 3696, 1) s_read_depth: (30, 3696, 1) cell_gene_state: (30, 3696, 2000) gene_ranking: mean_mae time_correlation mean_mae_rank time_correlation_rank \ genes Scg3 -0.809207 0.948156 134.0 311.0 Tuba1a -0.710443 0.931160 91.0 478.0 Cpe -0.539928 0.929520 36.0 492.0 Pcsk2 -0.710860 0.920191 93.0 556.0 Pim2 -1.023732 0.918140 275.0 576.0 ... ... ... ... ... Ubc -0.924188 -0.984542 194.0 9.0 Cox7a2l -0.602947 -0.985077 56.0 6.0 Ube2e3 -0.837889 -0.990080 147.0 3.0 Spint2 -0.466256 -0.991123 20.0 2.0 Calm2 -0.470297 -0.991592 21.0 1.0 rank_product selected genes genes Scg3 41674.0 1 Tuba1a 43498.0 1 Cpe 17712.0 1 Pcsk2 51708.0 1 Pim2 158400.0 0 ... ... ... Ubc 1746.0 0 Cox7a2l 336.0 0 Ube2e3 441.0 0 Spint2 40.0 0 Calm2 21.0 0 [300 rows x 6 columns] original_spaces_embeds_magnitude: (30, 3696) genes: ['Scg3', 'Tuba1a', 'Cpe', 'Pcsk2'] vector_field_posterior_samples: (30, 3696, 2) vector_field_posterior_mean: (3696, 2) fdri: (3696,) embeds_magnitude: (30, 3696) embeds_angle: (30, 3696) ut_mean: (3696, 2000) st_mean: (3696, 2000) pca_vector_field_posterior_samples: (30, 3696, 50) pca_embeds_angle: (30, 3696) pca_fdri: (3696,)
from pyrovelocity.analysis.analyze import top_mae_genes
volcano_data = posterior_samples["gene_ranking"]
number_of_marker_genes = min(
max(int(len(volcano_data) * 0.1), 4), 6, len(volcano_data)
)
putative_marker_genes = top_mae_genes(
volcano_data,
mae_top_percentile=3,
min_genes_per_bin=3,
)INFO pyrovelocity.analysis.analyze Selected 28 genes based on top 3% MAE from 8 time correlation bins, with a minimum of 3 genes per bin, sorted by time correlation: ['Cpe', 'Fam183b', 'Gnas', 'Iapp', 'Aplp1', 'Bex2', 'Ins1', 'Ins2', 'Emb', 'Cck', 'Gars', 'Camk2n1', 'Ypel3', 'Glud1', 'Selm', 'Btg2', 'Ttr', 'Tmsb4x', 'Atp6v0b', 'Marcks', 'Krt7', 'Spp1', 'Ctrb1', 'H3f3b', 'Actg1', 'Actb', 'Malat1', 'Spint2']
from pyrovelocity.plots import plot_gene_ranking
vector_field_basis = (
model2_postprocessing_inputs.preprocess_data_args.vector_field_basis
)
cell_state = model2_postprocessing_inputs.preprocess_data_args.cell_state
plot_gene_ranking(
posterior_samples=[posterior_samples],
adata=[adata],
selected_genes=putative_marker_genes,
time_correlation_with="st",
show_marginal_histograms=True,
save_volcano_plot=True,
volcano_plot_path="model2_volcano_plot.pdf",
)display(Image(filename=f"model2_volcano_plot.pdf.png"))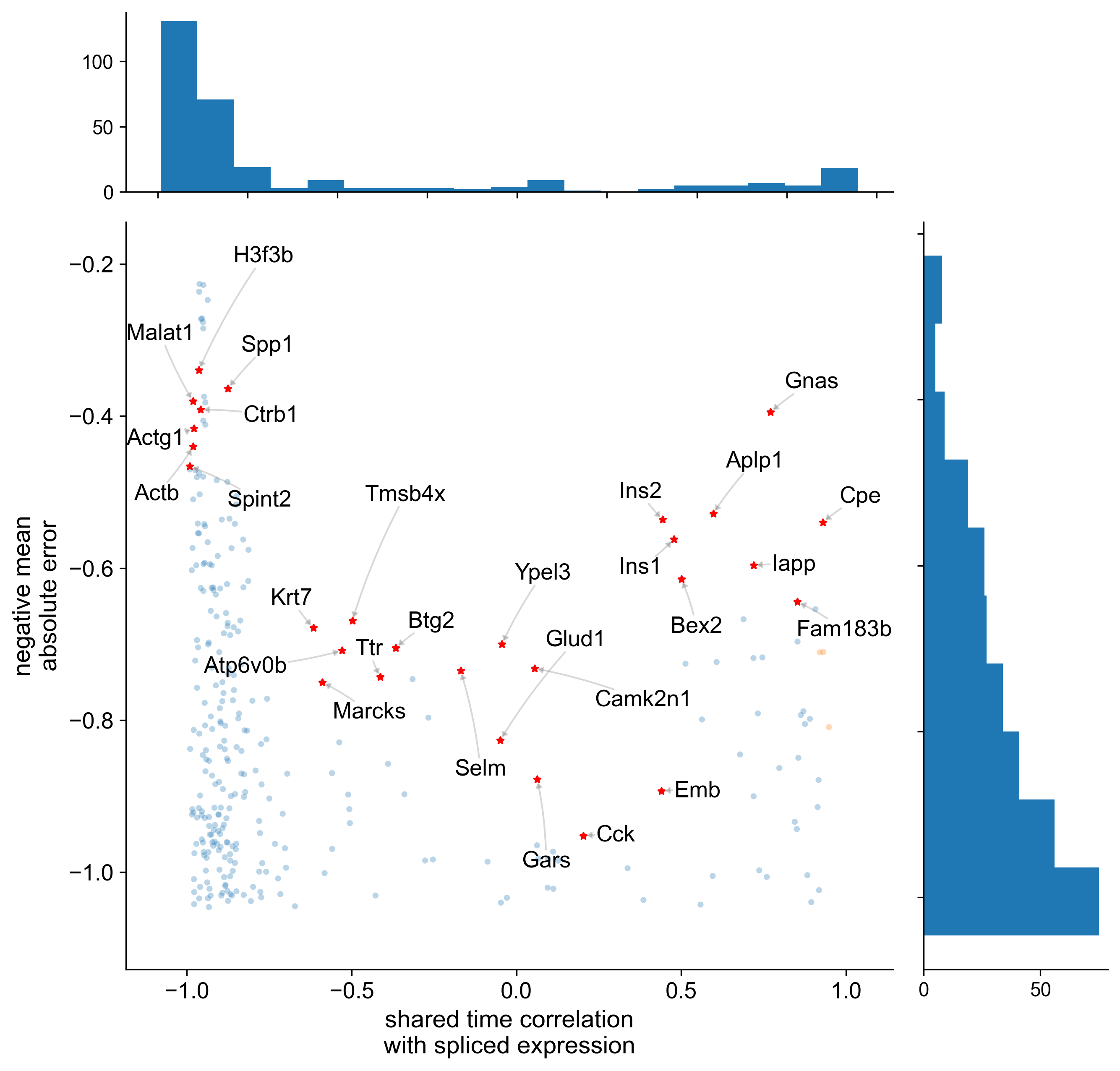
Plot phase portraits, predictive expression, and log-transformed expression of all proposed marker genes
from pyrovelocity.plots import rainbowplot
rainbowplot(
volcano_data=volcano_data,
adata=adata,
posterior_samples=posterior_samples,
genes=putative_marker_genes,
data=["st", "ut"],
basis=vector_field_basis,
cell_state=cell_state,
save_plot=True,
rainbow_plot_path="model2_rainbow_plot.pdf",
)display(Image(filename=f"model2_rainbow_plot.pdf.png"))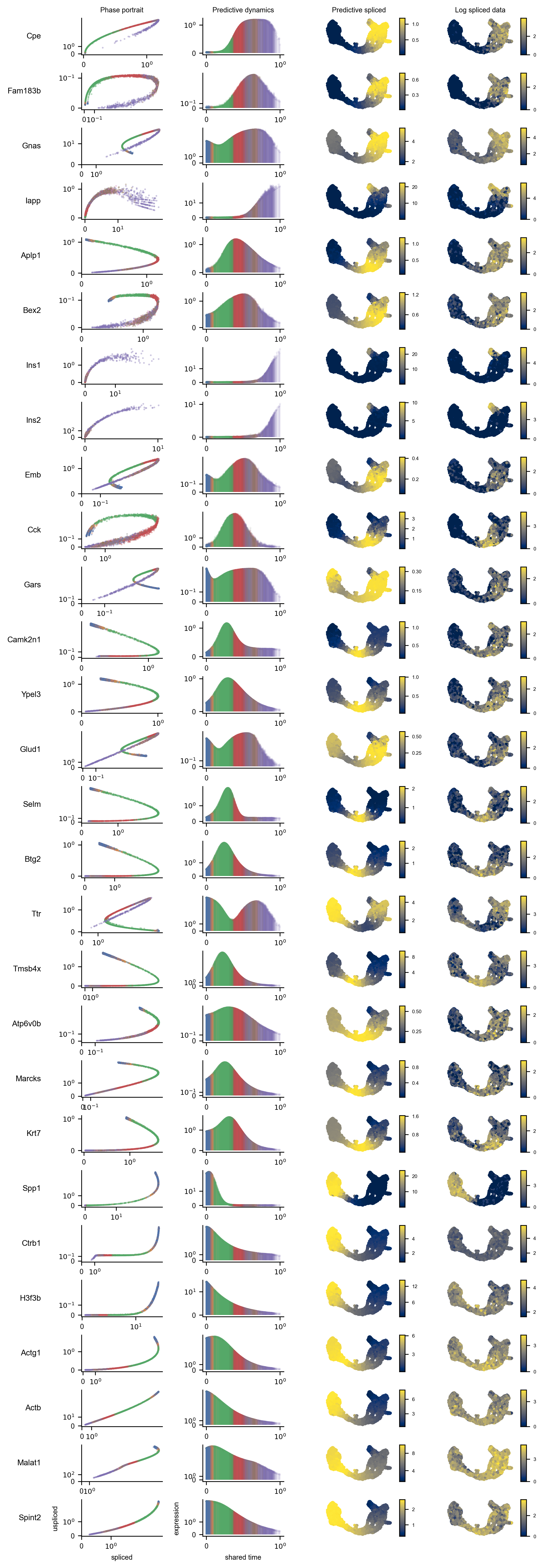
Finally, we plot the parameter posteriors for the second model.
from pyrovelocity.plots import plot_parameter_posterior_distributions
plot_parameter_posterior_distributions(
posterior_samples=posterior_samples,
adata=adata,
geneset=putative_marker_genes,
parameter_uncertainty_plot="model2_parameter_uncertainty_plot.pdf",
)display(Image(filename=f"model2_parameter_uncertainty_plot.pdf.png"))